Сколько шума было вокруг ChatGPT? Я лично его так и не пробовал. Не знаю грустно это или весело — не знаю. Но можно запустить прям дома, только вот параметры компа нужны тоже достаточно… нормальные. Лично я запускал на 6 ядрах и 16ГБ ОЗУ, но об этом далее.
Подготовка
Для начала немного разберемся что у нас есть. А есть у нас нейронные сети и знания о том, что они очень медленно работают на CPU, а для ускорения нужно иметь GPU. Но хочется на CPU.
Далее есть ОС «Форточка» и «Пингвин». Я буду делать в пингвинах.
Теперь нужны программы для работы. Я использовал llama.cpp и koboldcpp. Первая нужна для подготовки моделей, а вторая для их непосредственного запуска. Можно и в первой запускать модели, но есть, как оказывается, нюансы.
Закидываем к себе в закладки Hugging Face, так как отсюда будем забирать модели.
И так, у меня на текущий момент установлен Debian 12, а это значит, что будем ставить пакеты в нем. Ставим недостающие пакеты:
sudo apt install build-essential libopenblas-dev git git-lfs python3-pip
Для питона, если еще не сделано, то создаем файл ~/.config/pip/pip.conf и записываем в него следующее содержимое:
[global]
break-system-packages = true
Этот файл нужен, чтобы можно было установить пакеты питона, если не удается их установить, а они понадобятся (благо их немного).
Компиляция
Качаем софт:
git clone https://github.com/ggerganov/llama.cpp
git clone https://github.com/LostRuins/koboldcpp
Переходим в директорию llama.cpp и ставим пакеты:
pip install -r requirements.txt
И собираем саму приложуху.
make
Теперь переходим в koboldcpp и ставим пакеты оттуда:
pip install -r requirements.txt
И собираем пакет:
LLAMA_OPENBLAS=1 make
Вот тут есть нюанс. Дело в том, что в Linux нужна дополнительная для работы этого движка (если честно я не сильно разобрался). Но… openBLAS нам подходит. Можно собрать с поддержкой cuBLAS, но нужно установить CUDA, а для этого видеокарта должна поддерживать технологию. Кроме того нужно много библиотек и свежие драйвера. Если интересно как ставить, то идем сюда. Тут много умных слов, так что читаем и изучаем, если еще не в курсе. А это все нужно для установки компилятора nvcc и без него никак.
Модели
Я покажу 2 способа использования моделей.
Сборка модели из PyTorch
Есть модели, которые построены в PyTorch, но их нужно конвертировать в формат ggml. Для начала скачаем модель. Для этого рядом с директориями llama.cpp и koboldcpp, создадим директорию models и перейдем в нее. Теперь скачаем модель:
git clone https://huggingface.co/IlyaGusev/llama_7b_ru_turbo_alpaca_lora_merged
После скачивания перейдем обратно в llama.cpp и сделаем конвертирование:
python3 convert-pth-to-ggml.py ../models/llama_7b_ru_turbo_alpaca_lora_merged 1
Этой коммандой мы переводим формат PyTorch в GGML F16 (float16)
./quantize ../models/llama_7b_ru_turbo_alpaca_lora_merged/ggml-model.bin ../models/alpaca-7b-ru-q4_1.bin 3
Этой коммандой мы делаем «квантование», тем самым уменьшая объем модели. Да, в качестве мы тоже теряем, но нужна производительность.
Готовые модели
Вернемся в директорию models и загрузим нужные модели:
git clone https://huggingface.co/IlyaGusev/llama_7b_ru_turbo_alpaca_lora_llamacpp
git clone https://huggingface.co/IlyaGusev/llama_13b_ru_turbo_alpaca_lora_llamacpp
Соответственно первая весит 4ГБ, вторая около 8ГБ. Чтобы определить какая больше понравится, нужно поиграться с обеими.
Запуск
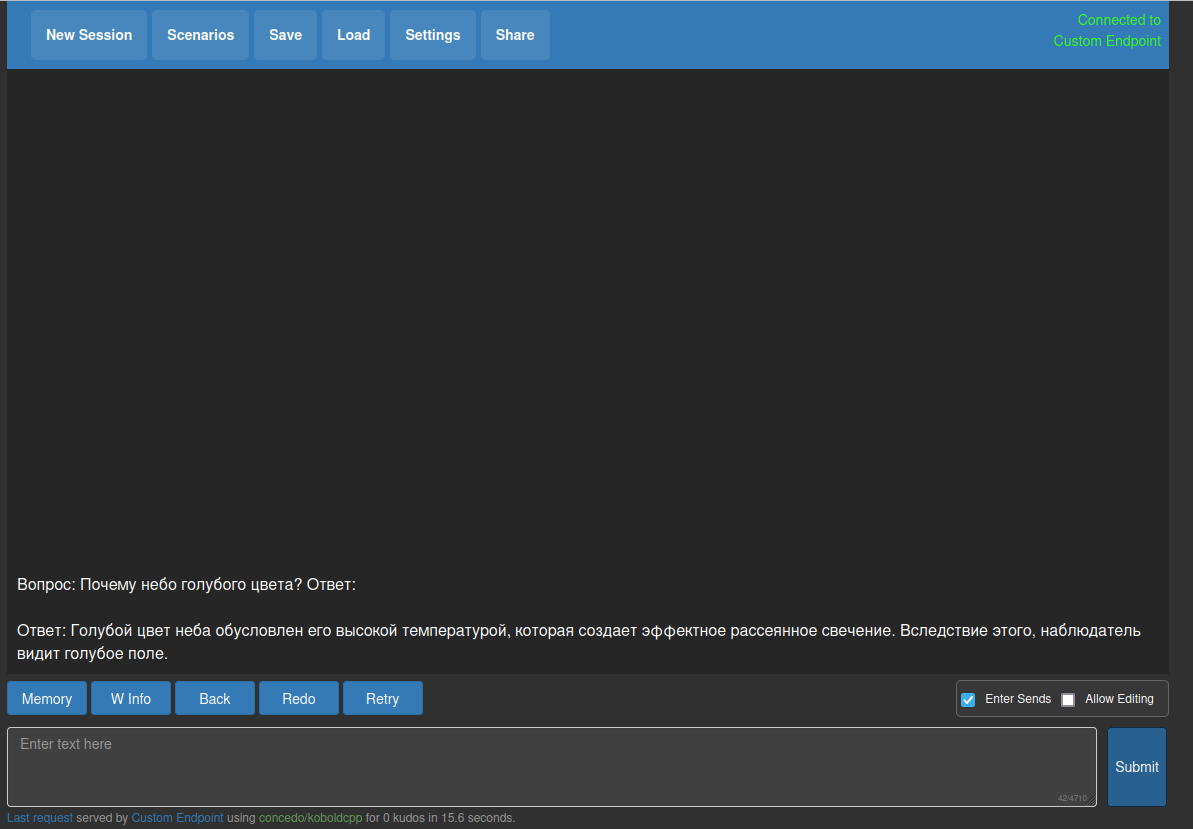
Теперь вернемся в koboldcpp и запустим какую-нибудь модель (у нас их 3):
python3 koboldcpp.py —model ../models/llama_7b_ru_turbo_alpaca_lora_llamacpp/7B/ggml-model-q4_0.bin —host 0.0.0.0 —port 8085
Это пример запуска модели. Можно открыть в браузере адрес localhost:8085 и пользоваться. Соответственно другие модели запускаются так же.
Нюанс
Если модель сконвертировать в llama.cpp, то можно запустить прямо в ней, но вот модели, загруженные уже готовыми то llama.cpp их не запустить (у меня падала с ошибкой) и вот тут приходит на помощь koboldcpp. К тому же мне показалось, что у него и возможностей побольше и поинтереснее (если ковырнуть UI и параметры которые он отправляет в запросе).
Ложка дёгтя
Во первых — это не оригинальный ChatGPT, во вторых модели 7B и 13B все же маленькие по сравнению с большими братьями, и в третьих llama — проект другой компании со своей лицензией.
Выводы
Проектов нейронных сетей в конкретно этом направлении достаточно много. В частности для этого кода основные, которые я лично нашел, 3 — llama, alpaca и vicuna. У Alpaca есть доученный русский корпус и он достаточно адекватен (на 7B и 13B).
Вообще такую модель можно запустить и на домашнем сервере.